
Introduction
Entre un tracking server-side et client-side, le volume de données collectées peut varier de 20 à 40%. Scripts bloqués par un adblocker, restrictions de navigateurs (Safari, Firefox) ou problèmes de chargement côté site en sont généralement la cause.
Une différence qui peut impacter vos analyses et vos budgets publicitaires et qui explique pourquoi de plus en plus d'équipes marketing se tournent vers le tracking server-side.
Les deux grandes méthodes de tracking
En 2026, le marketing repose principalement sur la data. Et lorsqu'il s'agit de tracker un site web, deux méthodes s’imposent :
↳ Client-side = tracking exécuté dans le navigateur
↳ Server-side = tracking exécuté depuis votre serveur
Le tracking “Client-Side”
Quand on parle de tracking client-side, cela signifie que les scripts sont chargés dans le navigateur et s’exécutent sur l’appareil de l’utilisateur. C’est aujourd’hui la méthode la plus utilisée, popularisée par de nombreux outils (GA4, Meta Pixel, etc.) et leur script de suivi simple à intégrer.
Mais le tracking client-side est pourtant souvent imparfait.
Car ces scripts populaires sont souvent reconnus et bloqués par défaut par les adblockers. Par conséquent, de nombreuses données ne sont jamais collectées, ce qui fausse les résultats d’analyse de conversion.
💡 30 à 35 % de l’ensemble des internautes utilisent aujourd’hui un bloqueur de publicités sur leurs appareils (soit environ 1 utilisateur sur 3).
Et c’est là que le server-side peut changer la donne…
Le tracking “Server-Side”
Avec le tracking server-side, une partie (ou l’intégralité) du tracking ne passe plus directement par le navigateur, mais par votre propre serveur.
Le workflow change, et la collecte de données s’opère de la manière suivante :
- L’utilisateur effectue une action (page vue, envoi de formulaire, clic sur un bouton)
- Le site envoie l’événement à votre serveur
- Le serveur envoie ensuite l’événement aux outils d’analyse (Analytics, Ads, CRM)
Et à la différence du Client-Side, le server-side n’est pas bloqué par les adblockers car l’URL ou le pattern est beaucoup plus complexe à identifier. Vous n’utilisez plus une configuration analytics par défaut, mais une URL de serveur rattachée à votre domaine, par exemple : tracking.digidop.com.
De plus, cette approche permet de mieux contrôler et filtrer les informations avant leur transmission aux outils analytics ou publicitaires.
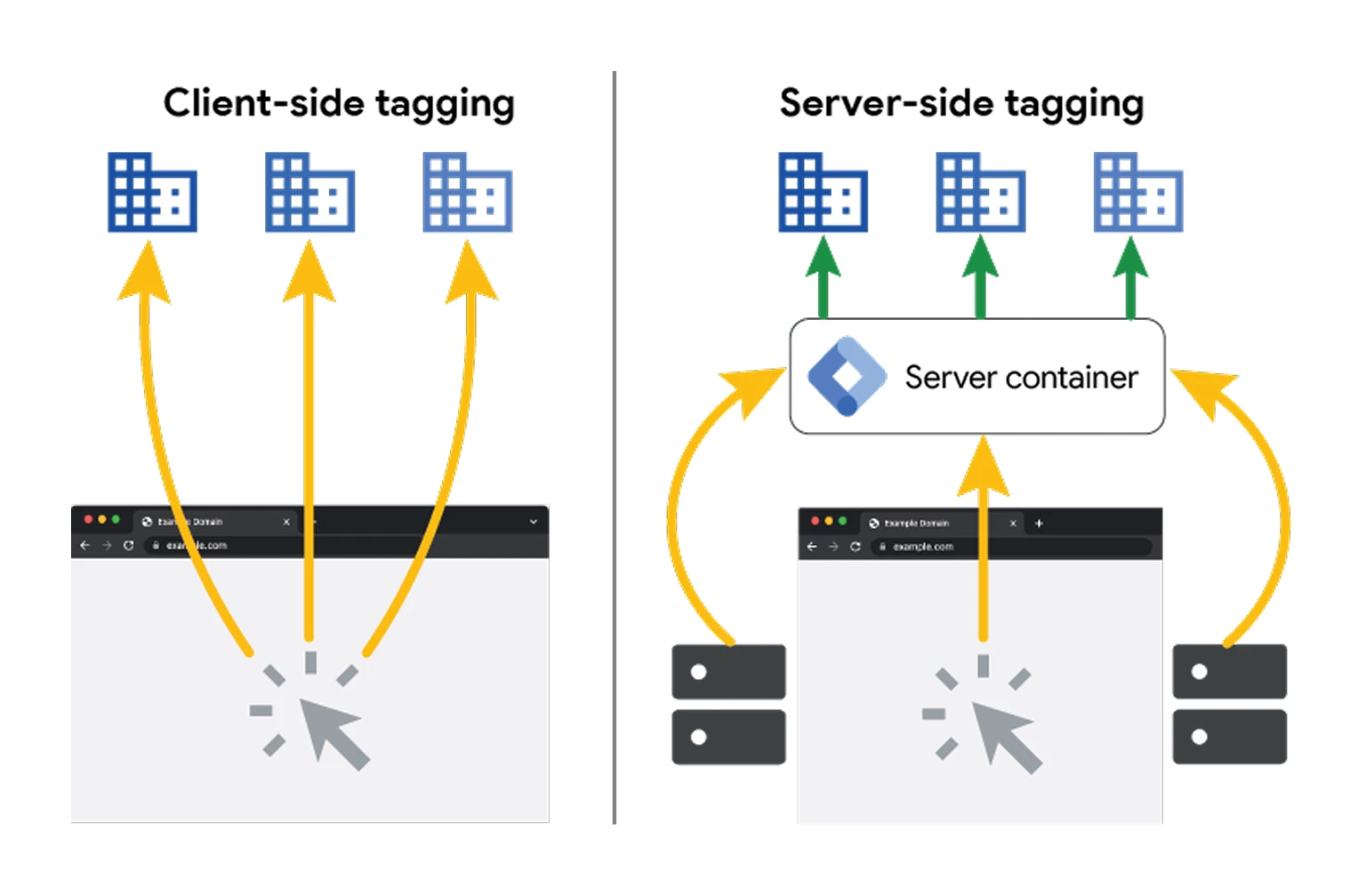
Client-Side VS Server-Side : Comparaison
Pour mieux comprendre les différences entre les deux approches, voici un comparatif synthétique.
⚠️ Attention : le server-side seul ne suffit pas pour tout traquer.
Les interactions utilisateur ont lieu dans le navigateur. Le server-side n’intervient qu’ensuite, pour fiabiliser, enrichir et redistribuer la donnée.
Dans quel cas privilégier le Server-Side ?
Le server-side est souvent plus coûteux et structurant à mettre en place. Tous les projets n’en ont donc pas besoin et le client-side peut largement suffire pour un site cherchant simplement un aperçu de ce qui se passe sur son site.
Mais alors, comment savoir si vous en avez besoin ?
Voici un questionnaire pour vous aider à identifier vos besoins :
→ Si vous cochez 2 cases ou plus, le server-side peut vous faire gagner en performance.
✅ Votre budget publicitaire dépasse 5 000€/mois (Meta, Google Ads)
✅ Vous constatez un écart important entre vos conversions trackées et vos ventes réelles
✅ Vous faites de l’ A/B testing ou travaillez activement votre CRO
✅ Votre trafic Safari/iOS représente plus de 20% de vos visiteurs
✅ Vous avez des enjeux de conformité RGPD stricts
✅ Votre site charge trop de scripts tiers et ralentit
Comment intégrer un tracking Server-Side sur son site ?
À la différence du client-side, où il suffit de copier/coller les scripts fournis dans le code ou à l’emplacement prévu par votre CMS, le server-side est plus complexe. Voici deux options que nous recommandons.
Option 1 : Créer un serveur container (technique)
Il est possible de créer son propre serveur, qui centralise les événements du site, permet de les traiter et de les redistribuer vers les outils d’analytics, CRM ou publicitaires selon les règles définies. Cette approche offre une flexibilité et un contrôle total sur la donnée, mais nécessite des compétences techniques pour la mise en place, l’hébergement et la maintenance du serveur.
Outil recommandé : Google Tag Manager (Server-Side)
À venir : nous travaillons sur notre propre tutoriel pour vous expliquer, étape par étape, comment créer votre serveur container. Il sera prochainement partagé dans notre newsletter.
Option 2 : Utiliser un outil clé en main (payant)
Des outils SaaS proposent des solutions clé en main qui prennent en charge l’hébergement et la configuration du serveur, tout en offrant une intégration simplifiée et un support dédié, moyennant un abonnement mensuel ou annuel.
Outil recommandé : Stape (Solution hébergée pour utiliser Google Tag Manager côté serveur)
{{custom-blog-cta}}
Conclusion et recommandations finales
Vous l'aurez compris : il n'y a pas de "meilleure" méthode.
Le server-side fait sens si vous avez d'importantes dépenses en ads, que vous avez besoin de données fiables pour optimiser vos campagnes, ou si votre trafic justifie l'investissement technique. Il vous donne un contrôle total sur votre collecte de données avant qu'elles n'arrivent dans GA4, Meta ou bien votre CRM.
Mais le client-side suffit amplement si vos besoins restent basiques et que vous voulez juste suivre ce qui se passe sur votre site sans complexité.
Enfin, il est important de rappeler que l’une n’exclut pas l’autre. Une collecte client-side peut être couplée à un enrichissement server-side. C’est même l’approche la plus performante, car tout faire en server-side n’est ni possible ni pertinent : le client-side est indispensable pour capter les interactions utilisateur, tandis que le server-side intervient pour fiabiliser, enrichir et contrôler les données avant leur exploitation.
💡 Point d'attention RGPD : Quelle que soit l'approche, le consentement reste obligatoire pour les données personnelles. Le server-side facilite la conformité mais ne vous en dispense pas.
Ressources complémentaires
- https://stape.io/blog/what-is-server-side-tracking
- https://developers.google.com/tag-platform/learn/sst-fundamentals (Service Side Tagging fundamentals courses)




.jpg)
